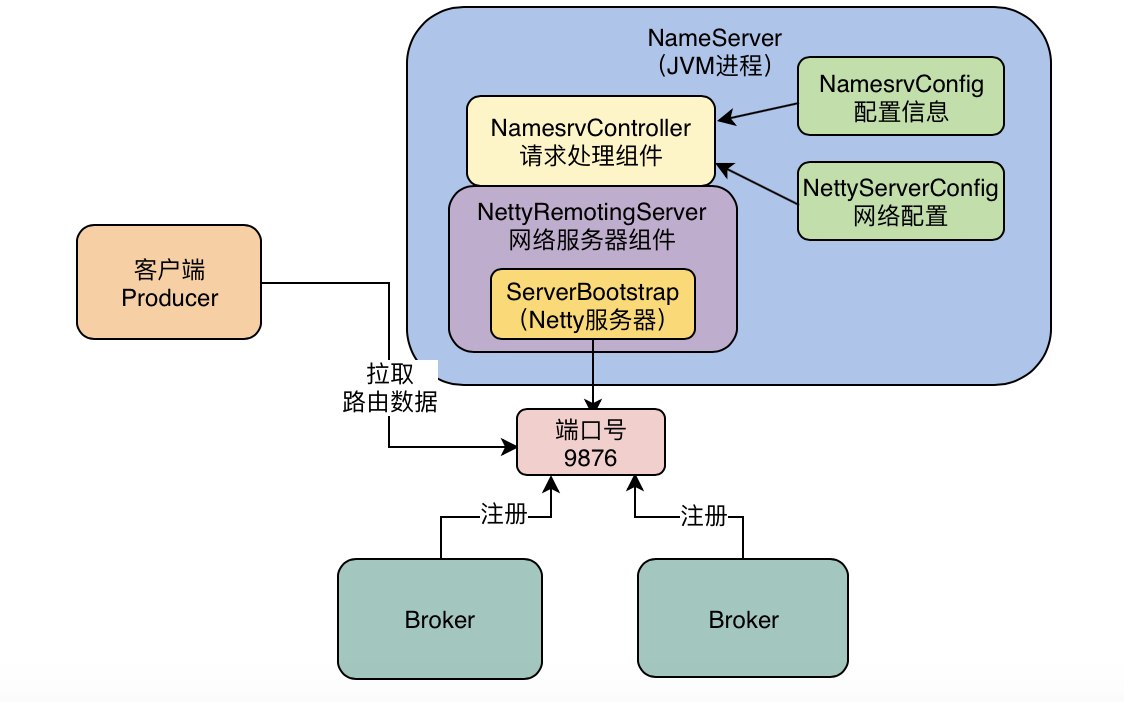
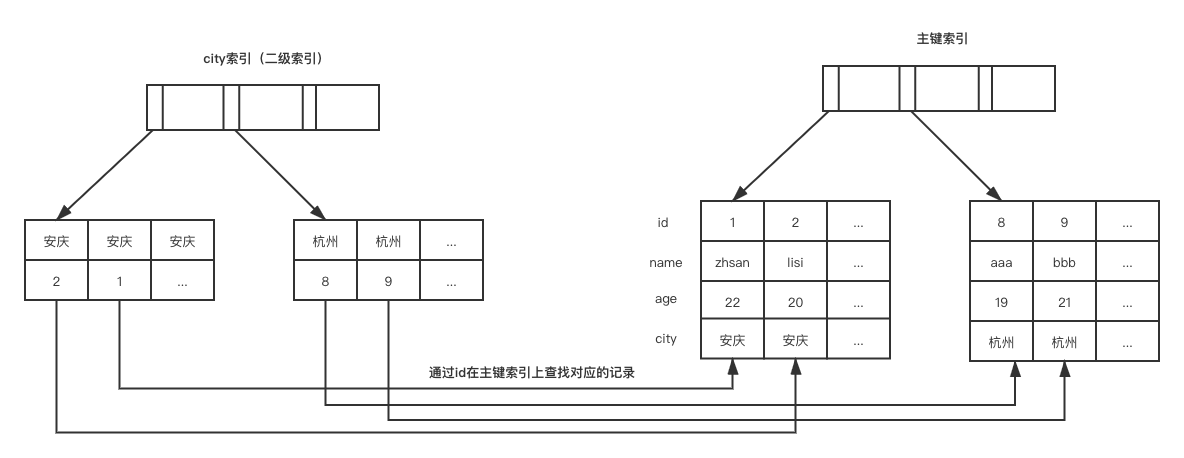
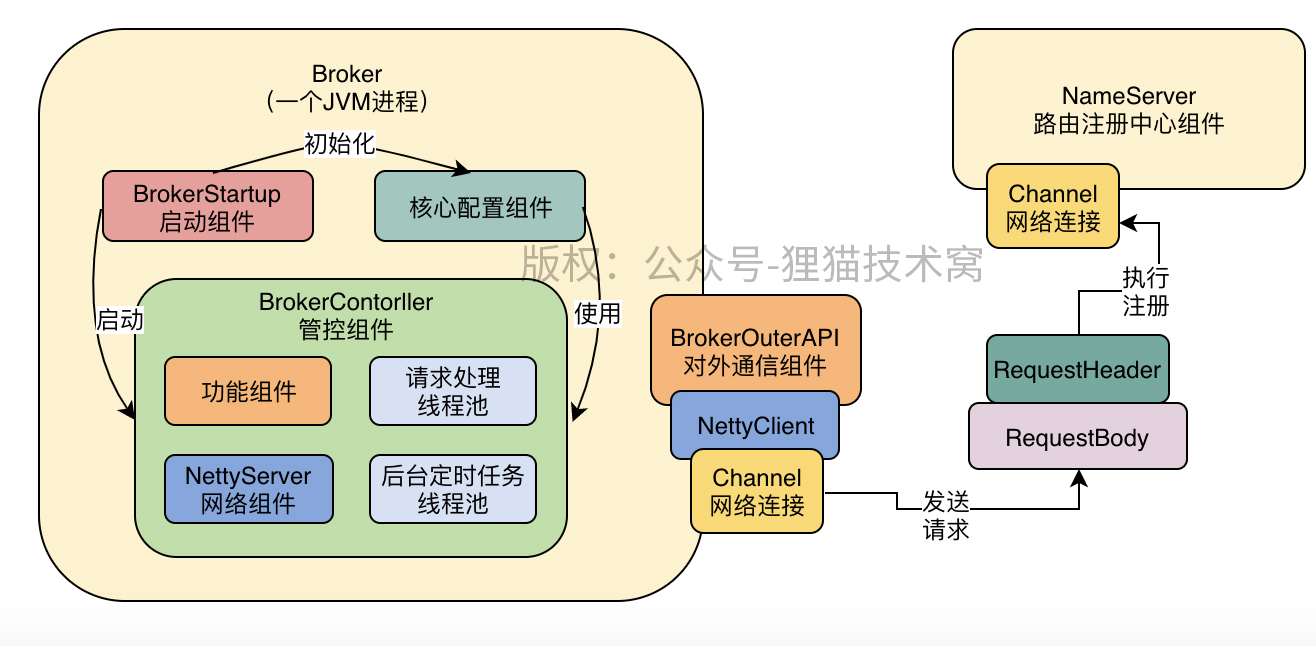
Broker服务注册
BrokerOuterAPI
服务注册
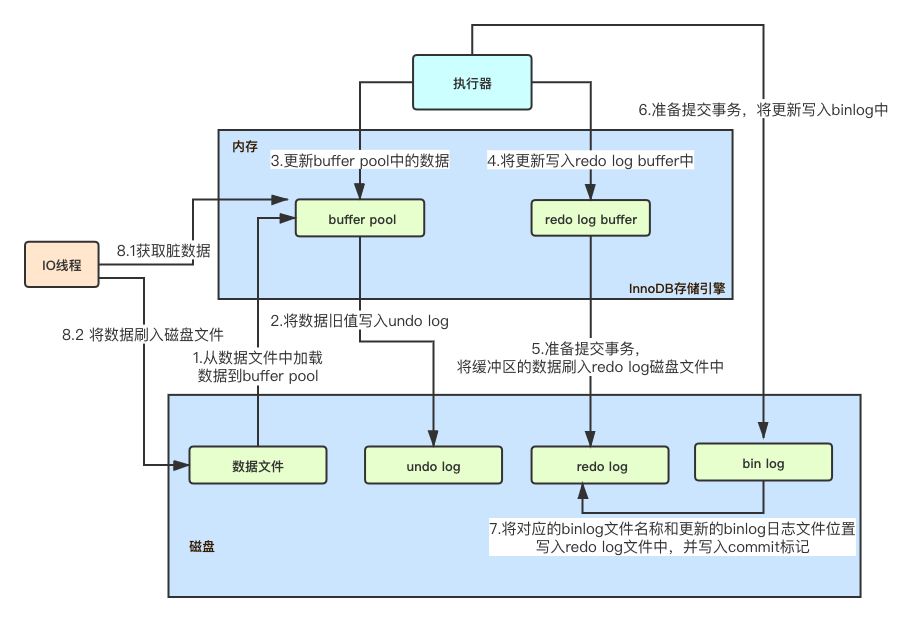
Broker服务注册的详细代码在BrokerOuterAPI的registerBrokerAll方法中:
1.构建Request请求头和请求体,并设置相关的参数;
2.因为Broker会向所有的NameServer注册,所以构建CountDownLatch,用来等待向所有的NameServer注册的任务都执行完毕;
3.使用线程池执行向每一个NameServer注册的任务,底层是通过Netty Client向NameServer发送注册请求的;
4.将注册结果放入结果集中,等待所有NameServer执行完毕返回结果列表;
1 | // 注册的详细代码 |
服务注册请求的发送
进入到registerBroker看一下服务注册请求发送的详细代码,可以看到底层是使用Netty Client进行请求发送的:
1 | private RegisterBrokerResult registerBroker( |
NettyRemotingClient
进入NettyRemotingClient中的invokeSync方法,看下详细的发送过程:
1.获取一个Channel,也就是获取和NameServer的一个连接,在获取Channel的时候首先会从缓存中获取Channel,如果没有获取到才会创建新的Channel;
2.调用invokeSyncImpl方法,通过Channel向NameServer发送请求;
1 |
|
创建Channel的代码:
1 | // 创建Channel |
发送网络请求的代码:
1 | // 发送网络请求的代码 |
心跳机制
为了让NameServer感知到Broker是否有异常,Broker会定时发送心跳到NameServer,告诉NameServer自己的服务正常。
BrokerController
回到start方法中,可以看到注册了一个定时任务,定时会向NameServer进行注册,默认每30s进行一次注册:
1 | public void start() throws Exception { |
NameServer注册处理
Broker的注册请求处理
NamesrvController
回到NamesrvController的initialize方法中,有一个注册处理器的方法registerProcessor:
1 | public boolean initialize() { |
DefaultRequestProcessor
DefaultRequestProcessor的processRequest对请求进行处理,会判断请求类型,然后处理对应的请求,找到Broker的注册类型,可以看到调用registerBroker方法对Broker的请求进行处理,最终是调用RouteInfoManager的registerBroker进行注册的:
1 | public class DefaultRequestProcessor{ |
RouteInfoManager
RouteInfoManager的registerBroker对Broker进行了注册:
1.根据集群名称获取对应的broker集合,然后将当前的broker加入集合中;
2.根据Broker的name获取brokerAddrsMap,其中key为broker的id,value为IP+端口,然后处理重复数据,保证brokerAddrTable核心路由表同一个IP和端口只有一条记录;
3.判断是否是Master,如果是并且Topic发生了变化或者是Broker首次注册,将会创建或者更新当前broker的Topic队列信息;
4.记录当前Broker的LiveInfo,Broker每次定时发送请求作为心跳的时候,都会有一个新的BrokerLiveInfo记录Broker的注册信息,包括注册时间、连接channel等信息,后续可以用来感知Broker是否有异常;
1 | public RegisterBrokerResult registerBroker( |
异常感知
在NamesrvController的初始化方法中启动了一个定时任务,调用了routeInfoManager的scanNotActiveBroker方法扫描不活跃的Broker,默认10s扫描一次:
1 | public class NamesrvController { |
RouteInfoManager
RouteInfoManager的scanNotActiveBroker会扫描超时未发送心跳的Broker,默认是120s,如果超过120s没有收到心跳注册,就会移除Broker的路由信息:
1 | // 扫描不活跃的Broker |
注:图片来自于儒猿技术窝-从 0 开始带你成为消息中间件实战高手
参考
儒猿技术窝:从 0 开始带你成为消息中间件实战高手